

Natural Language Processing Algorithms (NLP AI)
Originally Posted On: https://devsdata.com/natural-language-processing-algorithms-nlp-ai/ NLP AI – Before Deep Learning Era Back in the days before the era — when a Neural Network was more of a scary, enigmatic...Friday, February 28th 2020, 1:10 pm

Originally Posted On: https://devsdata.com/natural-language-processing-algorithms-nlp-ai/
NLP AI – Before Deep Learning Era
Back in the days before the era — when a Neural Network was more of a scary, enigmatic mathematical curiosity than a powerful tool — there were surprisingly many relatively successful applications of classical mining algorithms in the Natural Language Processing Algorithms (NLP) domain. It seemed that problems like spam filtering or part of speech tagging could be solved using rather straightforward and interpretable models.
But not every problem can be solved this way. Simple models fail to adequately capture linguistic subtleties like context, idioms, or irony (though humans often fail at that one too). Algorithms based on overall summarization (e.g. bag-of-words) turned out to be not powerful enough to capture sequential nature of text , whereas n-grams struggled to model general context and suffered severely from a curse of dimensionality. Even HMM-based models had trouble overcoming these issues due to their their memorylessness.
First breakthrough – Word2Vec
One of the main challenges in language analysis is the method of transforming text into numerical input, which makes modeling feasible. It is not a problem in computer vision tasks due to the fact that in an image, each pixel is represented by three numbers depicting the saturations of three base colors. For many years, researchers tried numerous algorithms for finding so called embeddings, which refer, in general, to representing text as vectors. At first, most of these methods were based on counting words or short sequences of words (n-grams).
The initial approach to tackle this problem is one-hot encoding, where each word from the vocabulary is represented as a unique binary vector with only one nonzero entry. A simple generalization is to encode n-grams (sequence of n consecutive words) instead of single words. The major disadvantage to this method is very high dimensionality, each vector has a size of the vocabulary (or even bigger in case of n-grams) which makes modeling difficult. Another drawback to this approach is lack of semantic information. This means that all vectors representing single words are equidistant. In this embedding, space synonyms are just as far from each other as completely unrelated words. Using this kind of word representations unnecessarily makes tasks much more difficult as it forces your model to memorize particular words instead of trying to capture the semantics.

The first major leap forward for natural language processing algorithm came in 2013 with the introduction of Word2Vec – a neural network based model used exclusively for producing embeddings. Imagine starting from a sequence of words, removing the middle one, and having a model predict it only by looking at context words (i.e. Continuous Bag of Words, CBOW). The alternative version of that model is asking to predict the context given the middle word (skip-gram). This idea is counterintuitive because such model might be used in information retrieval tasks (a certain word is missing and the problem is to predict it using its context), but that’s rarely the case. Instead, it turns out that if you initialize your embeddings randomly and then use them as learnable parameters in training CBOW or a skip-gram model, you obtain a vector representation of each word that can be used for any task. Those powerful representations emerge during training, because the model is forced to recognize words that appear in the same context. This way you avoid memorizing particular words, but rather convey semantic meaning of the word explained not by a word itself, but by its context.
In 2014 Stanford’s research group challenged Word2Vec with a strong competitor: GloVe. They proposed a different approach, arguing that the best way to encode semantic meaning of words in vectors is through global word-word co-occurrence matrix as opposed to local co-occurrences as in Word2Vec. As you can see in Figure 2 the ratio of co-occurrence probabilities is able to discriminate words when compared to the context word. It is around 1 when both target words co-occur very often or very rarely with the context word. Only when the context word co-occurs with one of the target words is the ratio either very small or very big. This is the intuition behind GloVe. The exact algorithm involves representing words as vectors in a way that their difference, multiplied by a context word, is equal to the ratio of the co-occurrence probabilities.
Further improvements
Even though the new powerful Word2Vec representation boosted the performance of many classical algorithms, there was still a need for a solution capable of capturing sequential dependencies in a text (both long- and short-term). The first concept for this problem was so-called vanilla Recurrent Neural Networks (RNNs). Vanilla RNNs take advantage of the temporal nature of text data by feeding words to the network sequentially while using the information about previous words stored in a hidden-state.
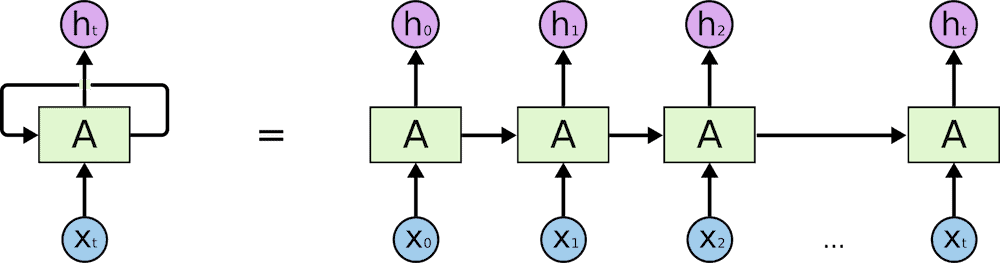
These networks proved very effective in handling local temporal dependencies, but performed quite poorly when presented with long sequences. This failure was caused by the fact that after each time step, the content of the hidden-state was overwritten by the output of the network. To address this issue, computer scientists and researchers designed a new RNN architecture called long-short term memory (LSTM). LSTM deals with the problem by introducing an extra unit in the network called a memory cell, a mechanism that is responsible for storing long term dependencies and several gates responsible for control of the information flow in the unit. How this works is at each time step, the forget gate generates a fraction which depicts an amount of memory cell content to forget. Next, the input gate determines how much of the input will be added to the content of the memory cell. Finally, the output gate decides how much of the memory cell content to generate as the whole unit’s output. All the gates act like regular neural network layers with learnable parameters, which means that over time, the network adapts and is better at deciding what kind of input is relevant for the task and what information can and should be forgotten.
LSTMs have actually been around since late 1990s, but they are quite expensive computationally and memory wise, so it is only recently, thanks to remarkable advances in hardware, that it became feasible to train LSTM networks in reasonable time. Nowadays, there exist many variations of LSTM such as mLSTM, which introduces multiplicative dependency on the input or GRU which, thanks to an intelligent simplification of the memory cell update mechanism, significantly decreased the number of trainable parameters.
After a short while it became clear that these models significantly outperform classic approaches, but researchers were hungry for more. They started to study the astounding success of Convolutional Neural Networks in Computer Vision and wondered whether those concepts could be incorporated into NLP. It quickly turned out that a simple replacement of 2D filters (processing a small segment of the image, e.g. regions of 3×3 pixels) with 1D filters (processing a small part of the sentence, e.g. 5 consecutive words) made it possible. Similarly to 2D CNNs, these models learn more and more abstract features as the network gets deeper with the first layer processing raw input and all subsequent layers processing outputs of its predecessor. Of course, a single word embedding (embedding space is usually around 300 dimensions) carries much more information than a single pixel, which means that it not necessary to use such deep networks as in the case of images. You may think of it as the embedding doing the job supposed to be done by first few layers, so they can be skipped. Those intuitions proved correct in experiments on various tasks. 1D CNNs were much lighter and more accurate than RNNs and could be trained even an order of magnitude faster due to an easier parallelization.
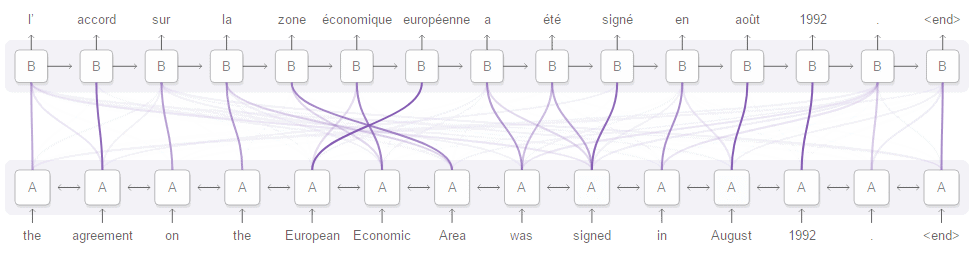
Despite incredible contributions made by CNNs, the networks still suffered from several drawbacks. In a classic setup, a convolutional network consists of several convolutional layers which are responsible for creating so-called feature maps and a module transforming it into predictions. Feature maps are essentially high level features extracted from text (or image) preserving the location where it emerged in the text (or image). The prediction module performs aggregating operations on feature maps and either ignores the location of the feature (fully convolutional networks) or more commonly: learns where particular features appear most often (fully connected modules). The problem with these approaches arises for example in the Question Answering task, where the model is supposed to produce the answer given the text and a question. In this case, it is difficult and often unnecessary to store all information carried by the text in a single text, as is done by classic prediction modules. Instead, we would like to focus on a particle part of text where the most crucial information is stored for a particular question. This problem is addressed by Attention Mechanism, which weighs parts of the text depending on what may be relevant based on the input. This approach has also been found useful for classic applications like text classification or translation. Will Attention transform the NLP field? llya Sutskever, Co-founder and Research Director of OpenAI stated in an interview:
I am very excited by the recently introduced attention models, due to their simplicity and due to the fact that they work so well. Although these models are new, I have no doubt that they are here to stay, and that they will play a very important role in the future of deep learning.”
llya Sutskever, OpenAI
Typical NLP problems
There are a variety of language tasks that, while simple and second-nature to humans, are very difficult for a machine. The confusion is mostly due to linguistic nuances like irony and idioms. Let’s take a look at some of the areas of NLP that researchers are trying to tackle (roughly in order of their complexity):The most common and possibly easiest one is sentiment analysis. This is, essentially, determining the attitude or emotional reaction of a speaker/writer toward a particular topic (or in general). Possible sentiments are positive, neutral, and negative. Check out this great article about using Deep Convolutional Neural Networks for gauging sentiment in tweets. Another interesting experiment showed that a Deep Recurrent Net could the learn sentiment by accident.

A natural generalization of the previous case is document classification, where instead of assigning one of three possible flags to each article, we solve an ordinary classification problem. According to a comprehensive comparison of algorithms, it is safe to say that Deep Learning is the way to go fortext classification.
Natural Language Processing Algorithms for Machine Translation
Now, we move on to the real deal: Machine Translation. Machine Translation has posed a serious challenge for quite some time. It is important to understand that this an entirely different task than the two previous ones we’ve discussed. For this task, we require a model to predict a sequence of words, instead of a label. Machine Translation makes clear what the fuss is all about with Deep Learning, as it has been an incredible breakthrough when it comes to sequential data. In this blog post you can read more about how — yep, you guessed it — Recurrent Neural Networks tackle translation, and in this one you can learn about how they achieve state-of-the-art results.
Say you need an automatic text summarization model, and you want it to extract only the most important parts of a text while preserving all of the meaning. This requires an algorithm that can understand the entire text while focusing on the specific parts that carry most of the meaning. This problem is neatly solved by previously mentioned attention mechanisms, which can be introduced as modules inside an end-to-end solution
Lastly, there is question answering, which comes as close to Artificial Intelligence as you can get. For this task, not only does the model need to understand a question, but it is also required to have a full understanding of a text of interest and know exactly where to look to produce an answer. For a detailed explanation of a question answering solution (using Deep Learning, of course), check out this article.
Since Deep Learning offers vector representations for various kinds of data (e.g., text and images), you can build models to specialize in different domains. This is how researchers came up with visual question answering. The task is “trivial”: just answer a question about an image. Sounds like a job for a 7-year-old, right? Nonetheless, deep models are the first to produce any reasonable results without human supervision. Results and a description of such a model are in this paper.
Natural Language Generation
You may have noticed that all of the above tasks share a common denominator. For sentiment analysis an article is always positive, negative or neutral. In document classification each example belongs to one class. This means that these problems belong to a family of problems called supervised learning. Where the model is presented with an example and a correct value associated with it. Things get tricky when you want your model to generate text.
Andrej Karpathy provides a comprehensive review of how RNNs tackle this problem in his excellent blog post. He shows examples of deep learning used to generate new Shakespeare novels or how to produce source code that seems to be written by a human, but actually doesn’t do anything. These are great examples that show how powerful such a model can be, but there are also real life business applications of these algorithms. Imagine you want to target clients with ads and you don’t want them to be generic by copying and pasting the same message to everyone. There is definitely no time for writing thousands of different versions of it, so an ad generating tool may come in handy.
RNNs seem to perform reasonably well at producing text at a character level, which means that the network predicts consecutive letters (also spaces, punctuation and so on) without actually being aware of a concept of word. However, it turned out that those models really struggled with sound generation. That is because to produce a word you need only few letters, but when producing sound in high quality, with even 16kHz sampling, there are hundreds or maybe even thousands points that form a spoken word. Again, researchers turned to CNNs and again with great success. Mathematicians at DeepMind developed a very sophisticated convolutional generative WaveNet model, which deals with a very large receptive field (length of the actual raw input) problem by using a so-called attrous convolutions, which increase the receptive field exponentially with each layer. This is currently the state-of-the-art model significantly outperforming all other available baselines, but is very expensive to use, i.e. it takes 90 seconds to generate 1 second of raw audio. This means that there is still a lot of room for improvement, but we’re definitely on the right track.
Recap
So, now you know. Deep Learning appeared in NLP relatively recently due to computational issues, and we needed to learn much more about Neural Networks to understand their capabilities. But once we did, it changed the game forever.
DevsData is a software and Machine Learning consulting company from New York City with extensive experience in Natural Language Processing.
Information contained on this page is provided by an independent third-party content provider. Frankly and this Site make no warranties or representations in connection therewith. If you are affiliated with this page and would like it removed please contact pressreleases@franklymedia.com

Get The Daily Update!
Be among the first to get breaking news, weather, and general news updates from News on 6 delivered right to your inbox!
More Like This

February 28th, 2020

January 19th, 2025

January 19th, 2025

January 19th, 2025
Top Headlines


January 19th, 2025

January 19th, 2025

January 19th, 2025